Vecchi cari framework ad agenti software oggi mi metto a giocare con i framework ad agenti AI. L’idea architetturale l’ho presa da CrewAI. La macroarchitettura è semplice ed efficace ma essendo fatta in Python ha problemi come la gestione balorda delle dipendenze, l’impiego di fork dipendenti dal contesto operativo (risolta solo su Linux e forse Apple), alcune cose anche meno piacevoli, come la necessità di accedere al loro telemetry e quindi l’impossibilità di lavorare sotto proxy o peggio offline, ad altre centinaia di issue. Perciò mi sono detto, invece che passare 2 giorni a patchare una cosa che poi non funziona lo stesso me la rifaccio al volo.
Questo framework prevede l’utilizzo di due o più agenti software basati su LLM che dialogano tra loro. Ogni agente può utilizzare un diverso LLM (nell es. Docente usa Llama3 tramite Groq e Studente usa Ollama con Mistral7B) oppure possono condividere lo stesso modello. Nonostante ciò, ogni agente mantiene una personalità e un contesto separati e distinti. Questo framework di “dialogo interno” (inner dialog) tra agenti mira ad aumentare l’efficienza del ragionamento e delle prestazioni complessive rispetto all’uso di un singolo LLM. Può essere utilizzato per diversi scopi, come la risoluzione di problemi passo-passo, la simulazione di scenari o per attività creative e giochi di ruolo.
Con gli agenti si tira su un “Politburo” che ha un’obbiettivo “aziendale” e poi di volta in volta gli si affida un task da adempiere. Nell’esempio che segue ci sono un docente e uno studente che colloquiano sulla risoluzione di una semplice somma. Questa è la loro descrizione:
Il video che segue va visto con i sottotitoli, perché appunto Whisper allucina alla grande. A parte leggere la punteggiatura completamente a caso, e apparire indemoniato, sembra fare dei forti peti. Sono problemi che ho risolto nel progetto di traduzione dei video, ma siccome fa ridere molto, lo lascio così.
L’implementazione al momento prevede un’interazione sequenziale. Ma si possono prevedere flussi di lavoro in parallelo e gerarchici, utili ad esempio per creare un politburo di esperti con ruoli diversi che vengono interpellati dalla macchina a stati a seconda dello stato della lavorazione. Un classico esempio è il team di ingegneri come in MetaGPT.
Mi serviva un modo per condividere i miei youtuber preferiti, sopratutto i canali di scienza con i miei pargoli. Ho sviluppato allora una piccola suite di tools per il la traduzione automatica dei video. Con tutti gli strumenti a disposizione oggi giorno è stato sufficiente mettere insieme i mattoncini all’interno della pipeline che è composta co orientativamente:
llm a caso (in genere un’istanza locale di Mistral 8x7B moe) – Per controlli sintattici e modifiche al testo
Abbiamo discusso con un amico di come migliorare la parte relativa alla sincronizzazione. I tool che ci sono in genere forniscono una soluzione di compromesso, quella di effettuare lo stretch in base ai cursori temporali presenti sugli SRT, tuttavia non è soddisfacente (eufemismo). Ho pensato che la tecnica migliore dovesse passare ok per delle pause (che vanno bene se non eccessive) ma una parafrasi del testo (via llm) sopratutto quando serve sintetizzarlo per incastrarlo in slot temporali più brevi. Ma ci vuole un po’ di lavoro. E per la distinzione tra più voci (speaker identification o diarization) per cui cito i tools podalize, pyannote.audio, e una sua estensione, pyannote-whisper.
Qui si evince come coqui abbia problemi con l’italiano, lingua fortemente snobbata anche nel campo del training dei modelli vocali. In particolare ho dovuto fare necessariamente preprocessing dei file, eliminando i punti a fine riga. Ma non mancano le allucinazioni vocali sullo stile del pesce di Sensational Gianni. Spaventose.
Il mio Canale su Youku, e il Canale su BiliBili, contengono tutti i video.
Non sapendo più come imporre la matematica con simpatia ho pensato di inserire plugin in ogni gioco.
Dopo il successo sensoriale di ToddlerTouch…
Ho utilizzato Three.js per sviluppare ThreeMeth, un qualcosa che tirasse fuori delle operazioni random, con un livello crescende di difficoltà, ma con un po’ di gamification. Il succo è non impedire il videogioco, ma consentirlo sotto determinate condizioni, allenare anche un po’ le capacità logico numeriche oltre a quelle ludiche. A questo scopo ho anche sviluppato un plugin per Minecraft che consente di continuare il gioco solo se si continua a rispondere correttamente a delle semplici domande
Operation Mindcrime Videogames
Il tutto è corredato da altre applicazioni, ad esempio School Trainer sviluppato in React, che aiuta a migliorare la metabolizzazione mnemonica di nozioni come pronuncia e lettura con la strategia dell’apprendimento spaziato tipico delle flashcards.
Oltre a questo ho creato dei tools per tradurre automaticamente video dall’inglese e videogiochi in scratch. Imporre lo studio significherebbe farglielo odiare, non so cosa altro inventarmi.
Mi sono imbattuto in un comportamento di JavaScript che voglio annotarmi. In particolare la differenza tra le funzioni tradizionali e le arrow functions sulla gestione del contesto di this. Questa differenza di comportamento influisce sulle operazioni asincrone e sui callback. Me ne sono accorto scrivendo questo codice:
constructor(scene, text_string) { new FontLoader().load('fonts/helvetiker_regular.typeface.json', function (font) { const geometry = text_geometry(font, text_string); const mesh = new THREE.Mesh(geometry, fontMaterial); scene.add(mesh); this.mesh = mesh; // doesn't work, it's inside the scope of FontLoader()! self.mesh = mesh; // Useless, this is a class member, not an instance member. }); }
this è una parola chiave che viene legata dinamicamente in base al contesto in cui una funzione viene chiamata, non dove viene definita. Nell’esempio del codice sopra, viene utilizzata un’espressione di funzione tradizionale come callback per il metodo load. In questo caso, this all’interno del callback non si riferisce all’istanza della classe in cui il costruttore è definito, ma piuttosto al contesto in cui viene eseguito il callback, che probabilmente è il contesto globale o il contesto di FontLoader. Di conseguenza, l’assegnazione this.mesh = mesh non funziona come previsto.
Insomma da fuori (dall’istanza) mesh non era accessibile. Dunque mi sono detto, metto il mesh su una variabile di classe. Ma la conseguenza di questo comportamento è che quando istanziavo una nuova classe tutti gli update che effettuavo accedendo al membro mesh avevano effetto solo sull’ultima istanza, perché quella è una variabile di classe appunto, e non di istanza.
Non so se questa cosa fosse risolvibile in un altro modo. Ho scoperto che le arrow functions, introdotte in ES6, gestiscono la cosa in modo diverso. Non creano un proprio contesto this, ma catturano il valore di this del contesto circostante in cui la arrow function è definita. Nello snippet di codice che segue, viene utilizzata una arrow function come callback, quindi this all’interno del callback si riferisce correttamente all’istanza della classe, consentendo di impostare this.mesh come desiderato.
La differenza tra le funzioni tradizionali e le arrow functions ha implicazioni significative quando si lavora con operazioni asincrone e callback. Le arrow functions sono spesso preferite come callback perché mantengono il contesto corretto di this, consentendo di accedere alle proprietà e ai metodi dell’istanza della classe in modo coerente.
Così quando sparo i numeri nel gioco che sto facendo per cercare di far fare i compiti di matematica a qualcuno, le operazioni che cercano di dar fuoco alla fenice vengono impostate e lanciate correttamente.
Un’idea che avevo in testa da tempo per pubblicare online il proprio CV in facile da manutenere, snello, e soddisfacente dal punto di vista della dinamicità, delle operazioni di filtro e di ricerca. Le altre soluzioni a cui ho pensato, sono:
La classica redazione del proprio documento in Word. La più semplice probabilmente, senonché servono parecchi passaggi di drag&drop per customizzare il CV a seconda delle esigenze o per pubblicarlo online.
Manutenere un CV in Latex (con l’appoggio delle librerie UltraLatex) è forse una delle soluzioni migliori, perché consente di includere solo le sezioni di interesse e modificare facilmente (nell’accezione di facile di Latex) il layout ma anche in questo caso, nel momento in cui bisogna esportare in formati particolari o pubblicare online, ci sono parecchi svantaggi.
La soluzione di un CV su blog statico, come WordPress, non è soddisfacente perché dovrei inserire ogni item in un post differente per poterlo etichettare e comunque la ricerca per categorie e per tag sarebbe farraginosa. Per non parlare di come hanno reso inutilmente caotico l’editing sulla piattaforma un tempo più accessibile e intuitiva con il pasticcio dei paradigmi a blocchi e il mescidato plugin di gutenberg (disable it).
I file json sono strutturati in modo che possano essere semplici da mantenere. Ci sono plugin per gli editor più comuni, ma anche i vari online IDE curano il pretty format ed effettuano un check della sintassi del documento;
Ognuno può adattare le sezioni alle proprie esigenze, clonandole, modificando il layout, aggiungendole al routing, personalizzando i fogli di stile.
Si possono inserire comodamente tool per ordinamento, filtraggio e la selezione e per rendere dinamica a piacere la navigazione. Questa è una delle funzionalità che mi serviva di più, se dovevo costruire un CV Java Tailored ad esempio dovevo fare una ricerca dei progetti correlati, ora mi basta selezionare un menu dalla tendina e inviare l’hard link.
Si può inserire codice custom come per esempio un meccanismo che ho implementato per linkare automaticamente ad esempio, le pubblicazioni ai riferimenti che avevo annotato sulle work activities a partire dal tag di indicizzazione.
E’ predisposto per la localizzazione.
Insomma cose simpatiche. I json me li sono fatti fare dagli LLM, devo completarlo appena avrò tempo, a volte l’obbiettivo diventa il percorso stesso, poi mi scende la pigrizia e mi schiena sulla poltrona.
Le attività di ricerca del progetto sono state raccolte in un documento di Roadmap di 80 pagine, poi utilizzato come relazione finale. Un lavoro svolto in autonomia durante la progettazione della piattaforma, lo sviluppo di tutta l’architettura web e l’implementazione del pool di microservizi. A seguito di molteplici richieste al team di ricerca non avendo feedback abbandonai l’idea di pubblicare (c’era un template su Overleaf) perché ero impegnato da solo anche su diversi altri progetti complessi.
L’obiettivo era di permettere a due mondi che provengono da contesti strutturali e comunicativi diversi di coesistere, in particolare quello accademico e quello aziendale e industriale. Una delle criticità del progetto, era risolvere tale difficoltà di comunicazione, anche a livello ontologico e pratico, tramite sistemi di ricerca e raccomandazione. La soluzione è stata tradotta a livello architetturale nell’implementazione di un ambiente che rileva e consente ai punti di contatto di queste realtà di emergere. Tale operazione è supportata da un’analisi dei requisiti di tutti gli attori e le entità coinvolte a livello operativo e redazionale e dall’implementazione di servizi, moduli e componenti personalizzati atti a formare relazioni tra di esse.
Il motore dei microservizi, tra le altre funzionalità, tenta di classificare automaticamente le entità che fanno ingresso nella piattaforma sulla base di un’ontologia stabilita in precedenza, tramite una complessa attività di analisi ben documentata, e di classificatori addestrati appositamente a tale scopo a partire di una knowledge base recuperata autonomamente da degli agenti software tramite attività di arricchimento semantico sulle poche informazioni a disposizione (di fatto i temi della tassonomia di riferimento precedentemente stabilita.
Analisi Ontologica
All’interno della piattaforma vengono raccolte e messe in relazione informazioni legate ai settori industriali e di ricerca. Durante le fasi di popolamento dei repository (e.g., Elasticsearch, DB CMS, Microservices w/ JPA) e della loro fruizione vengono di volta in volta create relazioni tra le entità che convivono all’interno dei flussi operazionali.
Nel loro ciclo di vita tali entità vengono, qualora possibile, classificate, in modo che si possa successivamente eseguire due operazioni in mutua corrispondenza:
Profilazione – la descrizione di un’entità per mezzo di caratteristiche definite dagli utilizzatori
Raccomandazione – l’attività di propagazione di un’entità verso gli utilizzatori che sono i più interessati alla sua fruizione
E’ stata effettuata un’analisi estensiva del materiale a disposizione all’interno del caso di studio offerto dalla piattaforma, delle sorgenti di dato (vedi paragrafo Analisi delle Sorgenti di dato fisiche) che include le interviste con gli stakeholders, gli accademici e gli utilizzatori della piattaforma, e i servizi esterni al sistema (vedi paragrafo Analisi delle Sorgenti di dato esterne). Tale attività ha permesso di rilevare l’esistenza di una serie di tassonomie plausibili per la descrizione delle entità di STARTS (vedi paragrafo Tassonomie Rilevate), e in particolare l’emersione di una tassonomia che, prevalendo sulle altre, è stata analizzata statisticamente nel sottoparagrafo conclusivo (vedi paragrafo Tassonomia Emergente) e poi utilizzata per i processi di collocazione dei contenuti all’interno dello stesso spazio tassonomico. L’estrapolazione e l’analisi di altri dati analitici sui dati acquisiti, richiesta dal comitato di valutazione, sono state riportate in un paragrafo di appendìce.
Dato che l’ontologia deve esprimersi mediante un linguaggio che accomuni comparti di ricerca, aree didattiche, settori industriali, eterogenei tra di loro, tra le tassonomie analizzate ne è emersa una in particolare che meglio delle altre riesce a categorizzare tutte le entità presenti sul sistema, la tassonomia ERC – European Research Council.
Arricchimento Semantico
Una soluzione che consente in fase di bootstrap di arricchire semanticamente le voci di tassonomia partendo dalle loro descrizioni, ove presenti, o dal loro titolo che rappresenta bene un’area tematica di riferimento. Questa tecnica porta dei benefici ulteriori, consentendo come conseguenza di lavorare su due fronti: (i) arricchendo semanticamente anche le entità che popolano il sistema, se etichettate manualmente o (ii) tentare di classificare tali entità in base alla loro eventuale descrizione testuale.
Successivamente è stato più semplice etichettare e arricchire di metadati le entità che entravano in Starts in accordo con la tassonomia definita.
Relazioni Accademiche
In aggiunta alle funzionalità che mette a disposizione il pool di microservizi, che è specializzato nel recupero delle relazioni sulla base di una classificazione automatica di entità non classificate perché non completamente pertinenti con l’ontologia stabilita, si può effettuare uno studio ulteriore sul grafo delle relazioni emergenti dalle attività pubblicatorie dei ricercatori di ateneo che sono disponibili nella base di conoscenza della piattaforma.
Anche solamente una prima analisi visuale di un grafo estrapolato da tali relazioni consente di mettere in evidenza la qualità di tale rete di relazioni, e probabilmente fare valutazioni sulla qualità della ricerca. Ad esempio:
L’identificazione dei cluster e dei settori di ricerca chiusi. Ad un analisi di tali settori si potrebbero individuare relazioni interdisciplinari tra settori di ricerca differenti, o aprire alle collaborazioni tra team di ricerca con interessi simili o complementari;
Identificare dei cluster isolati o autoreferenziali, evidenziando i baronati, o in generale i nodi sovraccarichi o topic di ricerca estremamente interessanti ma poco sfruttati;
Effettuare l’analisi dei cluster costruiti sulla base di altri attributi (e.g., settore di interesse, SSD, ERC, ma anche dipartimento) mettendo in luce quali sono le collaborazioni tra i settori di ricerca (e.g., biologia / informatica hanno uno stretto legame interdisciplinare) o le relazioni tra i dipartimenti, e anche qui tentare di far emergere collaborazioni tra team, settori, dipartimenti con interessi affini non ancora rivelati;
E’ possibile effettuare delle operazioni di profilazione su base semantica perché, repository come quello di Unica Starts conservano in cache tutte le informazioni disponibili sulle pubblicazioni oltre a titoli e autori, anche abstract e testi completi ove disponibili.
Una categorizzazione semantica di queste informazioni può consentire il riconoscimento di pattern di ricerca discussi precedentemente;
Una classificazione non supervisionata o meta classificazione di questo tipo consentirebbe altresì di legare più facilmente la realtà di ricerca ad altre non attinenti (aziendale, etc.)
Relazioni tra i Codici
Mentre sistemavo le librerie dei grafi, che sto utilizzando in altri progetti le ho testate sui libri dei codici vigenti in Italia, ovvero su un database di tutti quei codici, dei testi normativi, attualmente validi e vigenti come fonti del diritto. Ho costruito una knowledge base strutturata con codici e decreti, implementando degli web scraper per alcuni siti di consultazione delle normative, dato che pare non ci sia interesse a costruire dei servizi per il recupero di informazioni strutturate, accessibili e pubbliche di tutta la cloaca delle leggi azzeccagarbugli fatte, rifatte e collegate a un decreto regio dell’800 e culminate in leggi ad personam sedimentatatsi poi grazie alla perenne connivenza degli scaldapoltrone dell’opposizione, mentre i rubagalline finiscono dentro per gli errori nella dichiarazione del 730.
Anche qui, un progetto di analisi dei grafi e dei testi può rivelarsi interessante per mettere in luce diversi aspetti come, ad esempio:
Lo studio della qualità e del peso delle relazioni tra le varie voci di un codice oppure tra i cluster che identificano codici differenti. Nella figura precedente ad esempio si vede che ci sono degli articoli di procedura penale molto citati da altri articoli di altri codici, ad esempio penale etc.
Capire se è possibile che ci sia uno sbilanciamento esagerato tra gli articoli, con un sovraccarico ad esempio su alcuni punti del codice. Banalmente un articolo mai citato anche dalla cassazione potrebbe rivelarsi deprecabile, un articolo troppo citato invece potrebbe essere eccessivamente generico.
Senza scendere in giudizi di valore potrebbe essere un test per un certo tipo di efficacia della norma (ovviamente si parla di efficacia processuale della norma). Una norma può non essere mai citata perché di fatto non ci sono infrazioni relative a quella norma e quindi non si ci sono processi che vertono sulla fattispecie disciplinata da quella norma. In altri termini potrebbe essere o estremamente efficace (perché non viene mai violata) o del tutto inefficace, perché neanche i giudici la prendono in considerazione (ovviamente se si tratta di una norma prescrittiva).
Può anche essere che una norma sia estremamente importante, come un assioma dal quale poi vengono generate tutte le norme appartenenti a quel codice. Probablmente ci sono già studi sull’analisi semantica delle norme, ma è un campo interessante. Perché studiare i casi, il loro significato, le loro relazioni, potrebbe banalmente mettere in luce i difetti del sistema giuridico, come gli aspetti di estrema ridondanza, o di contraddizione in alcuni casi.
Demo Funzione Costrittiva su AV
Lato Progetti sull’etica delle IA abbiamo anche una pubblicazione pronta a partire da un articolo scritto con la collega O. Loddo sull’Adim blog dove analizziamo lo stato dell’arte relativo all’uso delle tecnologie di IA nella gestione di flussi migratori e distinguono tre macrofunzioni dell’IA. In particolare, distinguendo: la funzione informativa, la funzione attiva, la funzione costrittiva.
A partire da tale distinzione, abbiamo i vantaggi e gli svantaggi derivanti da tali pratiche, e le ripercussioni etiche dell’utilizzo degli strumenti di IA nei contesti migratori.
Per divertimento ho implementato velocemente un caso d’uso virtuale di regola costrittiva all’interno del popolare sandbox game Minecraft. Il giocatore non riesce ad attraversare il passaggio che lo porta all’interno del deposito se in possesso di un’arma (nella fattispecie una spada).
Pubblicata inizialmente su Heroku un’app per fare scraping e aggiornare manualmente liste di IPTV. L’applicazione aveva uno scheduler per la verifica di tutte le fonti e metteva a disposizione delle API per il recupero di una KB ben strutturata di tutti i canali di streaming categorizzati anche per lingua e topic.
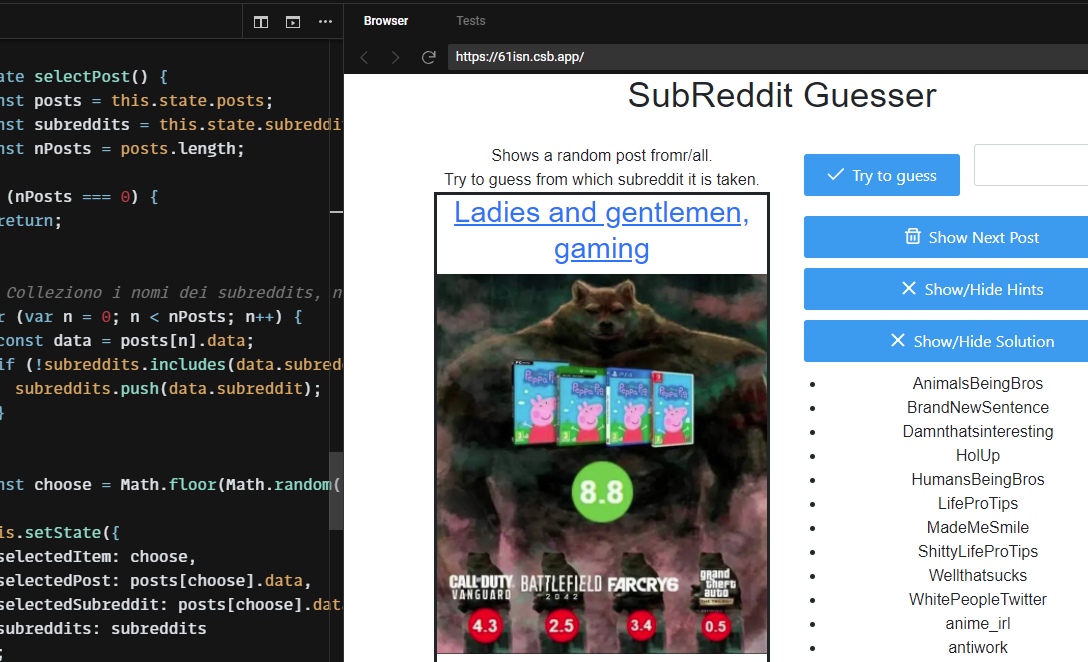
Ci giocavo sempre con il client mobile, partendo dalla fine e scorrendo verso l’alto. Mi serviva un’app che me lo rendesse semplice. Si tratta di prendere dei post di Reddit (l’ultimo social network che…) a caso e di vedere se si è in grado di stabilire da quale subreddit provengono (see Readme). Il codice è ospitato su CodeSandbox. Forkalo o miglioralo pure. Per giocare direttamente clicca qui.
Queue Calculator
Uno snack per la stima dei tempi di attesa in coda. Hai presente quando arrivi alle poste, e cerchi di stimare in base al numero di persone che servono quando è che toccherà a te? Questa applicazione effettua il calcolo automaticamente.
Un’app fatta al volo per il divertimento di un’amica. Da personalizzare all’occorrenza.
Covis News
Una semplice applicazione per tenere sotto controllo l’andamento del Covis, l’immunizzazione dura 6 mesi, il GreenPass 12, chi gira con gli starnuti al bar si può sedere, altrimenti devi stare al bancone a farti tossire in faccia da tipi con la gola rossa e il pass verde.
Ora mentre cercano di convincerci a fare la terza dose o la quarta, e mentre attendano che l’EMA dia il lascia passare per immunizzare anche gli embrioni in vitro e raggiungere finalmente il 140% dell’immunità del gregge di pecore che siamo (il 120% non è più sufficiente), avrai un’arma in più per tenerti informato. Personalizzabile in base alla tua location!
Syrene è un prototipo che collaziona una serie di moduli moduli e servizi che automatizzano le operazioni di amministrazione delle attività aziendali. Alcune funzionalità in fase di test comprendono:
Gestione Attività – Possibilità di inserire le giornaliere in maniera agile e di fare pianificazione. Ad esempio se si pianifica un attività di tot ore giornaliere per settimane è sufficiente una sola entry. Un ulteriore vantaggio è la delega alla compilazione di chi pianifica o chi esegue quell’attività effettivamente in modo da scaricare il coordinatore.
Interfacce ad hoc – Possibilità di inserire le giornaliere con un singolo tap su applicazione mobile, e avere uno specchio delle attività correnti a portata di click su qualsiasi tipologia di device. Vedi il video dimostrativo di Syrene Report.
Contabilità in ingresso – Possibilità di tracciare gli acquisti, di inventariarli, di conoscerne la posizione logistica in modo che si possa immediatamente stabilire la disponibilità di un oggetto e la sua collocazione fisica. Le fatture caricate vengono salvate in una gerarchia di cartelle pronta per essere consegnata insieme alla tabella corrispondente ai commercialisti.
Contabilità in uscita – Gestione di contabilità e fatturazione in uscita, con relazione su progetto, controllo immediato dei crediti non corrisposti, degli acconti per SAL o Saldi da corrispondere.
Gestione dei progetti – Controllo del loro stato, filtraggio, selezione, analisi delle attività correlate con tutte le informazioni su referenti, tabulazione di giornate e ore lavorate.
Contabilità Parametrica – E’ possibile associare dei parametri a entità ed eventualmente relazioni. Questo permette di effettuare un calcolo dinamico dei costi in base a un dato parametro configurabile.
Ho pubblicato su Netlify un prototipo in React puro che sfrutta il paradigma delle blockchain per l’implementazione di strumenti di certificazione a basso costo. Il prototipo consente di ragionare sulla possibilità di ospitare una blockchain personalizzata per le proprie esigenze di certificazione di informazioni o di atti sociali.
Alcuni esempi applicativi sui quali abbiamo ragionato comprendono:
Transazioni Certificate – Certificazione interazioni, ad esempio assistenza fiscale, rilascio documenti. Potrebbe svincolare dall’utilizzo di PEC o strumenti di firma digitale, rendere sicura la transazione, evitare situazioni di ambiguità legate alle attività svolte durante un processo produttivo. Certificabile con un piccolo codice, stampabile anche su un QR code.
Strumenti di Fidejussione Certificati – con transazioni garantite all’interno della catena
Certificazioni ISO – Verifica delle certificazioni, ovvero esecuzione di task con condizione tramite verifica su un dispositivo informatico. Utile per trattare con fornitori che non sono certificati ISO, magari con l’ausilio di strumenti embedded immediati, e.g., un pulsante di conferma e certificazione dell’avvenuta operazione in un certo luogo in una certa data. Sistema di qualità automatico. Svincolando dalle verifiche sul posto (se non quelle antifrode).
Borsa d’arte – Una borsa virtuale per scambio e scommesse su artisti emergenti e non.
Un prototipo che sposta l’onere computazionale client side con l’utilizzo di un browser o un dispositivo convenzionale è stato sviluppato per ragionare sull’utilità e l’efficacia di questa proposta. Il pregio di questo approccio è la completa libertà di customizzazione, l’indipendenza dai sistemi classici e quindi l’assenza di costi di transazione. I difetti sono dati da:
Impossibilità di garantire la tutela della catena senza un sistema di consenso distribuito
Impossibilità di certificare il timestamp delle transazioni
Alcuni di questi problemi sono ovviabili attingendo alle caratteristiche dei sistemi classici ove necessario:
Se tutti i possessori di un certificato conservano una copia della catena (sono incentivati a farlo per tutelare la validità del proprio certificato) il consenso è implementato
Se si utilizza un terzo servizio per la certificazione di un timestamp (basterebbe una conferma di certificazione via mail?)
Si possono anche ipotizzare le seguenti funzionalità:
Chi immette un payload paga computazionalmente in base alla dimensione del payload stesso. Questo dimostra la disponibilità a mettere a disposizione tempo computazionale per il mining e a disincentivare la pubblicazione di contratti troppo grossi, con ovvi vantaggi sul mantenimento del repository.
Nota: è un prototipo per lo studio e non tiene volutamente in considerazione la sicurezza del repository di appoggio.